


NVIDIA Unveils Nemotron-Cascade 2: A Breakthrough in AI Model Development
Recently, NVIDIA made waves in the AI community with the release of Nemotron-Cascade 2, an open-weight 30B Mixture-of-Experts (MoE) model featuring 3B activated parameters. This innovative model sets its sights on maximizing ‘intelligence density,’ offering advanced reasoning capabilities while using a fraction of the parameters compared to leading models.
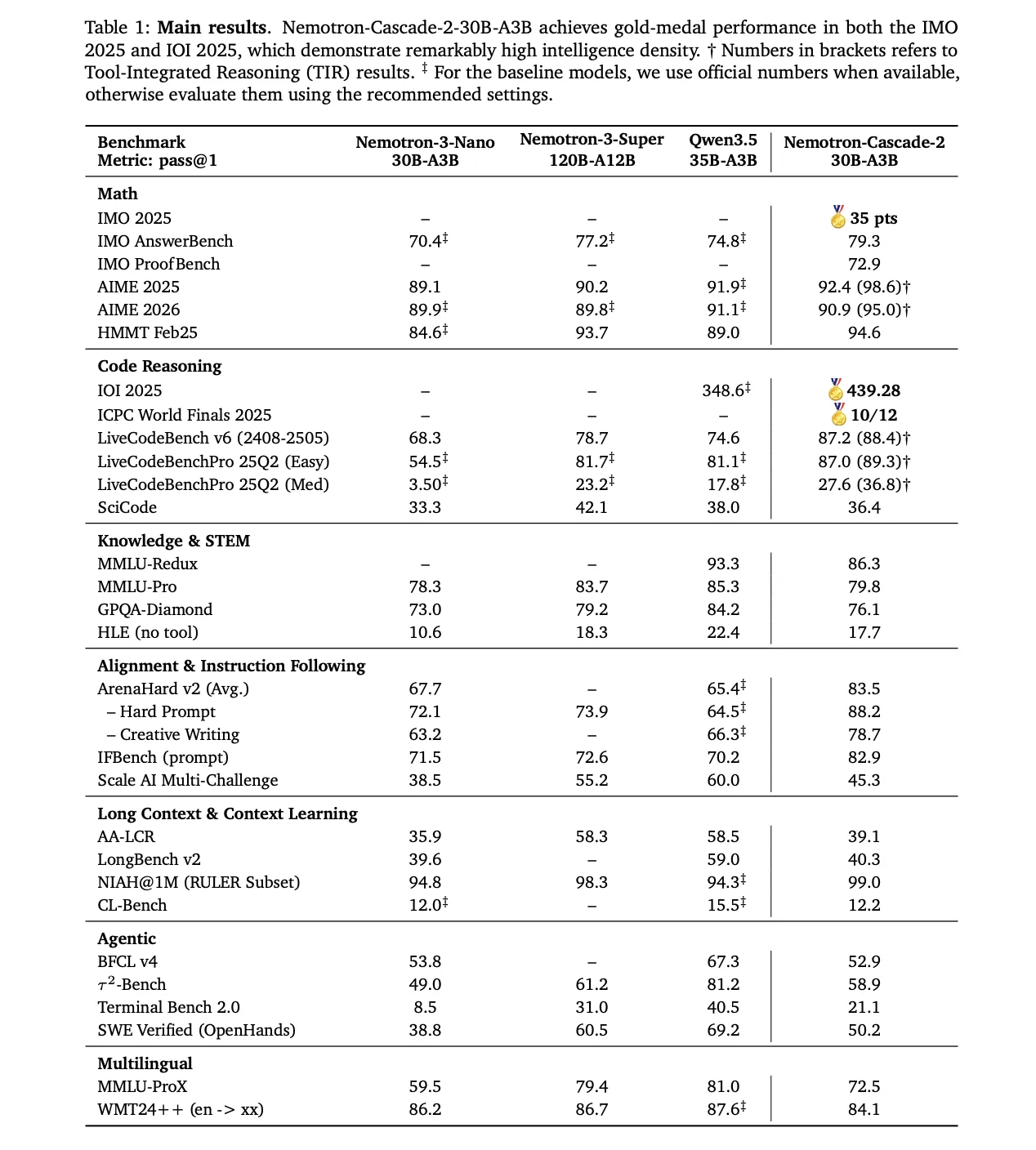
The standout achievement of Nemotron-Cascade 2 is its Gold Medal-level performance in prestigious competitions such as the 2025 International Mathematical Olympiad (IMO), the International Olympiad in Informatics (IOI), and the ICPC World Finals.
Targeted Performance and Strategic Trade-offs
Nemotron-Cascade 2 excels in specific domains such as mathematical reasoning, coding, alignment, and instruction following. While it showcases state-of-the-art results in these areas, it’s important to note that it may not be a one-size-fits-all solution for all benchmarks.
When compared to other models like Qwen3.5-35B-A3B and Nemotron-3-Super-120B-A12B, Nemotron-Cascade 2 demonstrates superior performance in mathematical reasoning, coding, alignment, and instruction following tasks.

Technical Architecture: Cascade RL and Multi-domain On-Policy Distillation (MOPD)
The foundational strength of Nemotron-Cascade 2 lies in its post-training pipeline, starting from the Nemotron-3-Nano-30B-A3B-Base model.
1. Supervised Fine-Tuning (SFT)
Throughout the process of Supervised Fine-Tuning (SFT), the NVIDIA research team leveraged a carefully curated dataset containing Python reasoning traces, tool-calling samples, mathematical natural language proofs, and specialized Software Engineering (SWE) data.
2. Cascade Reinforcement Learning
Cascade RL, a pivotal stage post SFT, involves sequential, domain-specific training to prevent catastrophic forgetting and tailor hyperparameters for specific domains without affecting others.
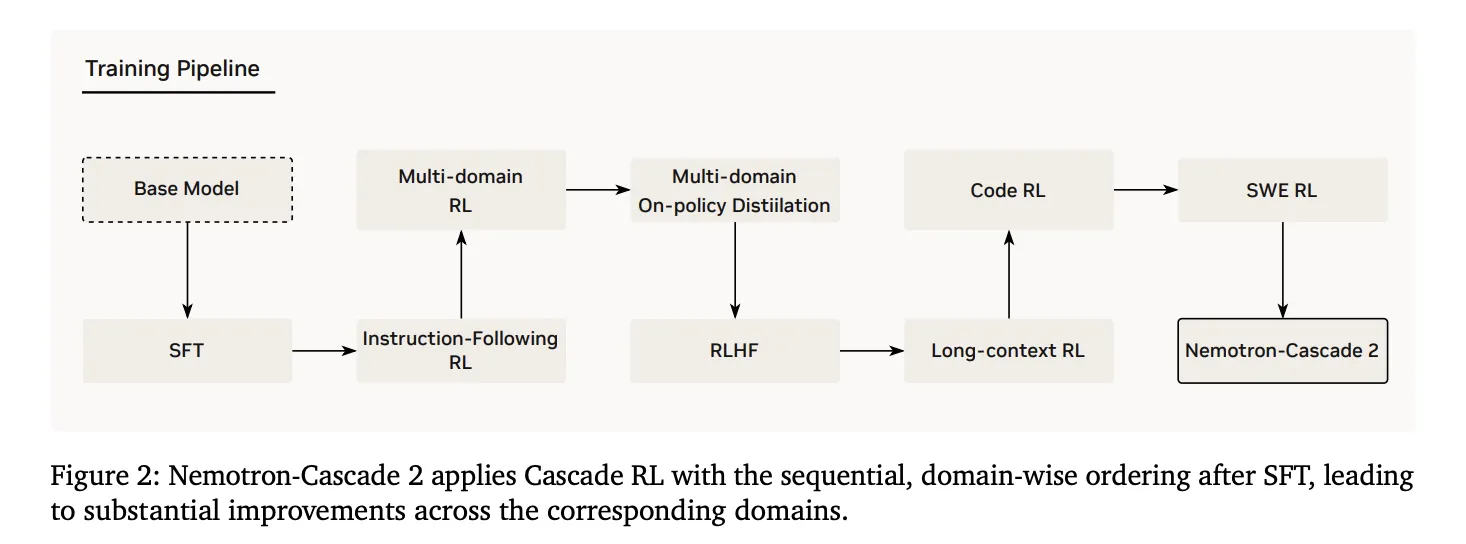
3. Multi-Domain On-Policy Distillation (MOPD)
Integrating Multi-Domain On-Policy Distillation (MOPD) during the Cascade RL process is a key innovation in Nemotron-Cascade 2. This approach leverages the best-performing intermediate ‘teacher’ models to enhance token-level distillation efficiency.
Inference Features and Agentic Interaction
Nemotron-Cascade 2 introduces two primary operating modes: Thinking Mode and Non-Thinking Mode, enabling deep reasoning for complex tasks and efficient responses, respectively. Additionally, the model incorporates a structured tool-calling protocol for agentic tasks.
By prioritizing ‘intelligence density,’ Nemotron-Cascade 2 showcases that specialized reasoning capabilities can be achieved at a 30B scale through domain-specific reinforcement learning.
For more details, check out the paper and model on HF. Stay updated by following us on Twitter, joining our ML SubReddit, and subscribing to our Newsletter.

Be the first to comment