

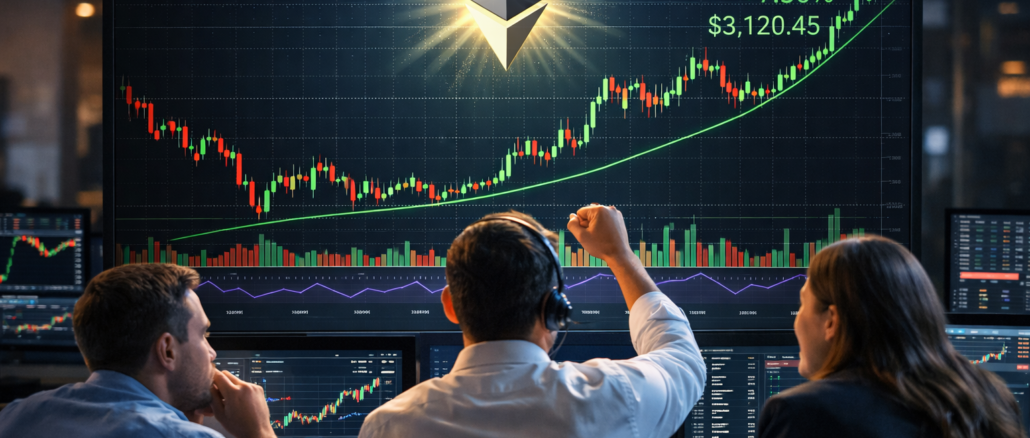
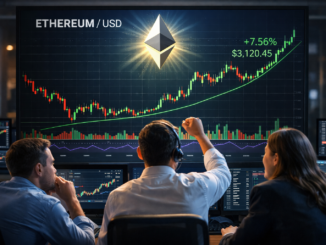
In the Spotlight
Crypto News April 05 2026 #Shorts #crypto #bitcoin
Check this video on YouTube

-
 Check this video on YouTube
Check this video on YouTube


























© Copyright 2026 TheCryptoNews.io